Information Gathering&scanning for sensitive information[ Reloaded ]
Testing Web-Application/Network , Information Gathering is important before we test for vulnerability on the target?

What kind of information we will gather for testing Web-application?
- whois lookup [ to gather information about registered company and their email for assetfinding]
- Horizontal domain correlation [ to find more horizontal domain for the company / finding acquisitions]
- Subdomain Enumeration / Vertical domain correlation [ to find vulnerability /security issue and gathering the targets assets]
- ASN lookup [Discovering more assets of the company using asn number]
- Target Visualize/Web-Screenshot [ also know as visual recon to see how the target looks like what feature visually available to test]
- Crawling & Collecting Pagelinks [ crawling the subdomains to get links and url of the domain]
- Javascript Files Crawling [ to find sensitive information like api key auth key , plain information etc.]
- Parameter discovery [ to scan for injection type vulnerability or other security issue]
- Subdomain Cname extraction [ to check if any domain is pointed to third party service later we can use those information for subdomain takeover]
- Domain/Subdomain Version and technology detection [ to map next vulnerability scanning steps]
- Sensitive information discovery [Using search engine to find sensitive information about the target]
Whois Lookup
To Check Other websites registered by the registrant of the site (reverse check on the registrant, email address, and telephone), and in-depth investigation of the target sites .
whois target.tldthis command will show you the whois result for the target.tld , the output of the whois scan result will contain information like nameserver registrant email , organization name , we could use those information to reverse whois lookup to find more asset of the target company.

we can filter and grep the email from here by just using grep and regex.
whois $domain | grep "Registrant Email" | egrep -ho "[[:graph:]]+@[[:graph:]]+"
Horizontal domain correlation/acquisitions
Most of The time we focus on subdomains ,but they skipout the other half aka Horizontal domain correlation .horizontal domain correlation is a process of finding other domain names, which have a different second-level domain name but are related to the same entity. [0xpatrik]
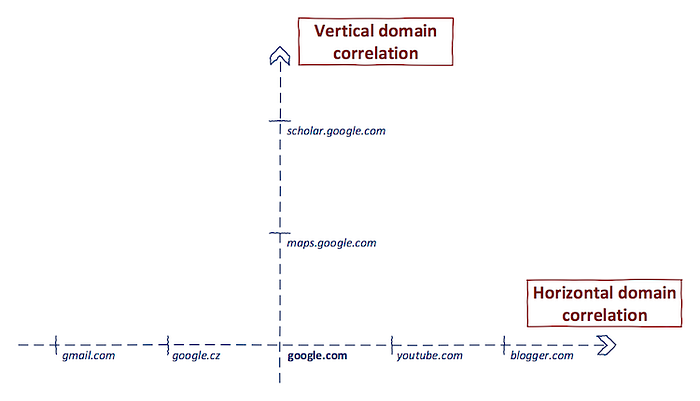
Firstly, let’s think about it. We cannot rely on a syntactic match as we did in the previous step. Potentially, abcabcabc.com and cbacbacba.com can be owned by the same entity. However, they don’t match syntactically. for this we can use the previous whois result where we collected email from whois result to do reverse whois search. there are lots of website available to do reverse whois lookup. now lets do a reverse whois lookup with the email we collected with this oneliner.
whois $domain | grep "Registrant Email" | egrep -ho "[[:graph:]]+@[[:graph:]]+"
---------------------------------------------------------https://viewdns.info/reversewhois/
https://domaineye.com/reverse-whois
https://www.reversewhois.io/
its waste of time to go to the website and lookup so many times , so i have created a bash script to do this search with bash from cli.
Subdomain enumeration
After collecting acquisitions for our target company , our first step is to enumerate subdomains for those collected domains. we can divide the enumeration process one is passive enumeration one is active enumeration . On passive enumeration process we will collect subdomains from different source of the website using tools , these tools collects subdomains from sources like [hackertarget , virustotal , threatcrowd , cert.sh etc] in active enumeration process we will use word-list with all our target domains to generate a permuted list and resolve them to check which are alive and vaild subdomains of target.
Passive enumeration
There are so many tools available on the internet to gather subdomain in passive method.
We can find subdomain using also google search using dorks example:
site:target.tldit looks complicated to collect subdomains from google , we can use bash to make it cli based script,
#!/usr/bin/bash
domain=$1
agent="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36"
curl -s -A $agent "https://www.google.com/search?q=site%3A*.$domain&start=10" | grep -Po '((http|https):\/\/)?(([\w.-]*)\.([\w]*)\.([A-z]))\w+' | grep $domain | sort -u curl -s -A $agent "https://www.google.com/search?q=site%3A*.$domain&start=20" | grep -Po '((http|https):\/\/)?(([\w.-]*)\.([\w]*)\.([A-z]))\w+' | grep $domain | sort -u curl -s -A $agent "https://www.google.com/search?q=site%3A*.$domain&start=30" | grep -Po '((http|https):\/\/)?(([\w.-]*)\.([\w]*)\.([A-z]))\w+' | grep $domain | sort -u curl -s -A $agent "https://www.google.com/search?q=site%3A*.$domain&start=40" | grep -Po '((http|https):\/\/)?(([\w.-]*)\.([\w]*)\.([A-z]))\w+' | grep $domain | sort -uor You can use this awesome tool from darklotuskdb
the result will be something like that
or we also can use shodan to find subdomain for target domain.the shodan query will be like.
hostname:"target.tld"or we can do the same thing from cli
shodan init your_api_key #set your api key on client
shodan domain domain.tldlets see some onliner those will help us to enumerate subdomain from different source
cert.sh
curl -s "https://crt.sh/?q=%25.target.tld&output=json" | jq -r '.[].name_value' | sed 's/\*\.//g' | sort -ucurl -s "https://riddler.io/search/exportcsv?q=pld:domain.com" | grep -Po "(([\w.-]*)\.([\w]*)\.([A-z]))\w+" | sort -ucurl "https://subbuster.cyberxplore.com/api/find?domain=domain.tld" -s | grep -Po "(([\w.-]*)\.([\w]*)\.([A-z]))\w+"certspotter
curl -s "https://certspotter.com/api/v1/issuances?domain=domain.com&include_subdomains=true&expand=dns_names" | jq .[].dns_names | tr -d '[]"\n ' | tr ',' '\n'SAN [ Subject Alternate Name ] domain extraction
These are little sample of the source to gather subdomains now lets know about SAN based subdomain enumeration S.A.N stands for Subject Alternate Name, The Subject Alternative Name (SAN) is an extension to the X.509 specification that allows to specify additional host names for a single SSL certificate.
Lets Write a Bash Script to extracts domain from ssl certificate using openssl.
sed -ne 's/^\( *\)Subject:/\1/p;/X509v3 Subject Alternative Name/{N;s/^.*\n//;:a;s/^\( *\)\(.*\), /\1\2\n\1/;ta;p;q; }' < <(openssl x509 -noout -text -in <(openssl s_client -ign_eof 2>/dev/null <<<$'HEAD / HTTP/1.0\r\n\r' \-connect sony.com:443 ) ) | grep -Po '((http|https):\/\/)?(([\w.-]*)\.([\w]*)\.([A-z]))\w+'
Dns Enumeration using cloudflare
wget https://raw.githubusercontent.com/appsecco/bugcrowd-levelup-subdomain-enumeration/master/cloudflare_enum.py# Login into cloudflare https://www.cloudflare.com/login# "Add site" to your account https://www.cloudflare.com/a/add-site# Provide the target domain as a site you want to add# Wait for cloudflare to dig through DNS data and display the resultspython cloudflare_enum.py your@email.com target.tld
All those time i was talking about and showing oneliner about single source to passively collect subdomains , but there are many tools those tool use all of these source to collect subdomains and filter unique thats how we get so many subdomains.
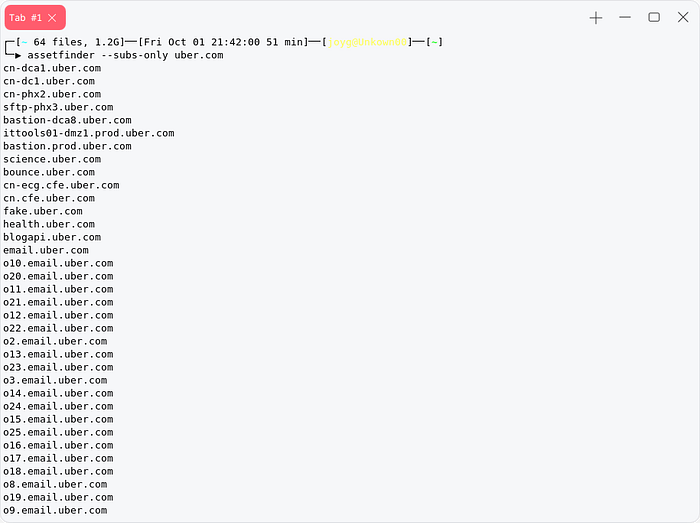
Assetfinder
go get -u github.com/tomnomnom/assetfinder #download the assetfinderassetfinder --subs-only domain.tld # enumerates the subdomain
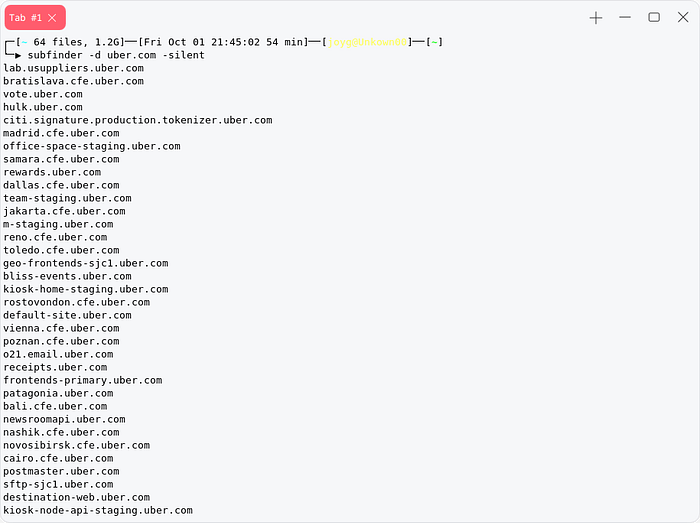
Subfinder
download https://github.com/projectdiscovery/subfinder/releases/tag/v2.4.8subfinder -d domain.tld --silent
findomain
findomain is mostly wellknow for its speed and accurate result , most of the time these tools like subfinder,findomain,assetfinder [ passive subdomain enumerators ] usage same process same api , the advantage of using all of them is no passively gathered subdomain gets missed.
download from [ https://github.com/Findomain/Findomain/releases/tag/5.0.0 ] findomain -t target.tld -q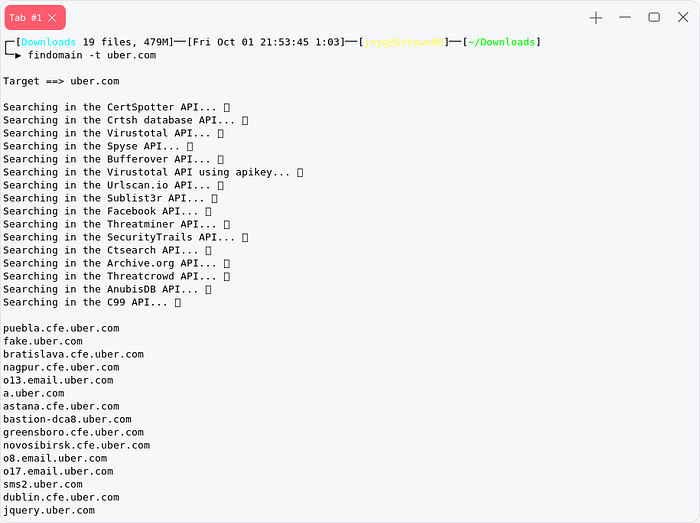
we can use more alternative to gather subdomains passively most of the time these tools usage same api same source to collect subdomains.
Active enumeration
In active enumeration process first we will permute our collected domain with our wordlist you can use any wordlist from sec-lists , jhaddix-all.txt . to get most of the subdomain i will suggest you to use big wordlist which contains more word to permute more subdomains. there are tools available which can do permutation and resolving in same time like amass . But this amass has some issue , we are gonna skip it . I will show you tool i use to generate dns wordlist.
GoAltdns is a permutation generation tool that can take a list of subdomains, permute them using a wordlist, insert indexes, numbers, dashes and increase your chance of finding that estoeric subdomain that no-one found during bug-bounty or pentest. It uses a number of techniques to accomplish this.
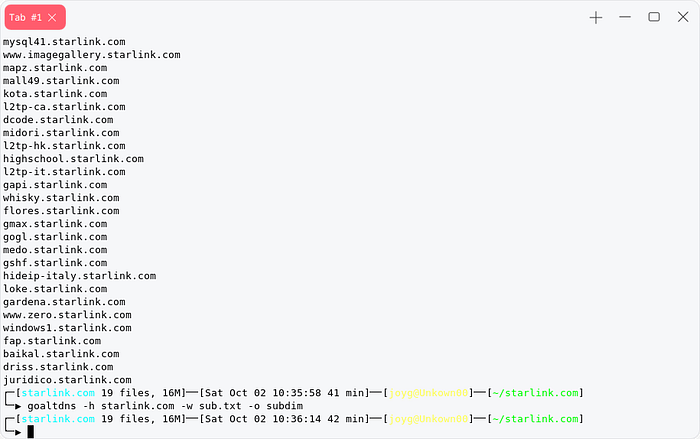
You can use Gotator as its alternative .
After Generating permutation , our first task is to resolve them to filter alive subdomains for this technique we will use massdns you also can use puredns. We can use this resolvers.txt . Now our first task is to mix all the subdomains we collected using passive scan and permutation .
cat passive-subs.txt perm.txt | sort -u | tee -a all-sub.txtMassdns
massdns -r resolvers.txt -t AAAA -w result.txt all-sub.txt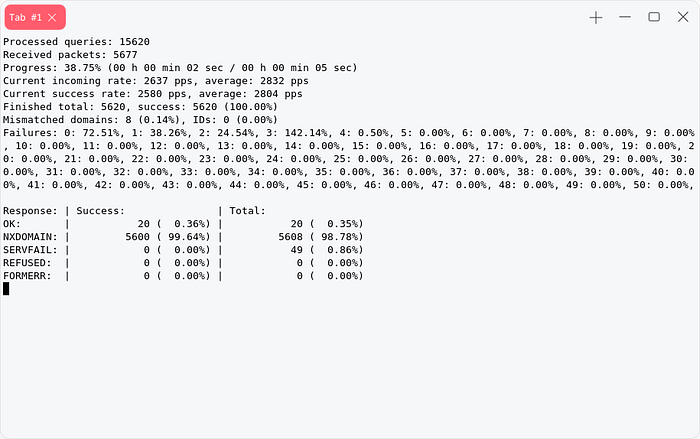
now lets mix the two tool goaltdns and massdns
goaltdns -h site.com -w all.txt | massdns -r resolvers.txt -t A -w results.txt -It will directly take output from goaltdns and resolve it.
this one is my favorite , it can permute and resolve at the same time.
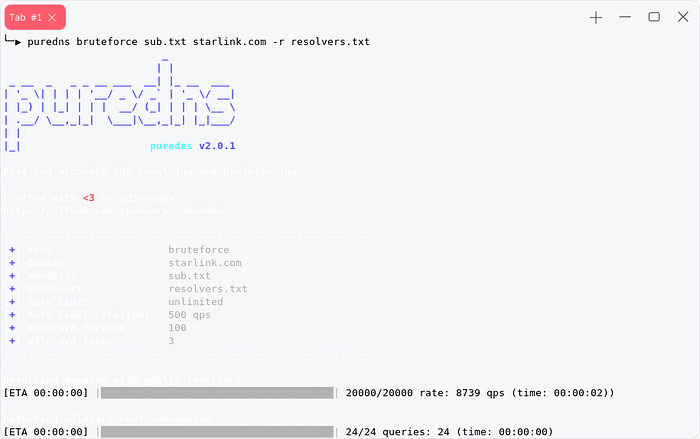
or We can use nmap to bruteforce for subdomain
Nmap
nmap --script dns-brute --script-args dns-brute.domain=uber.com,dns-brute.threads=6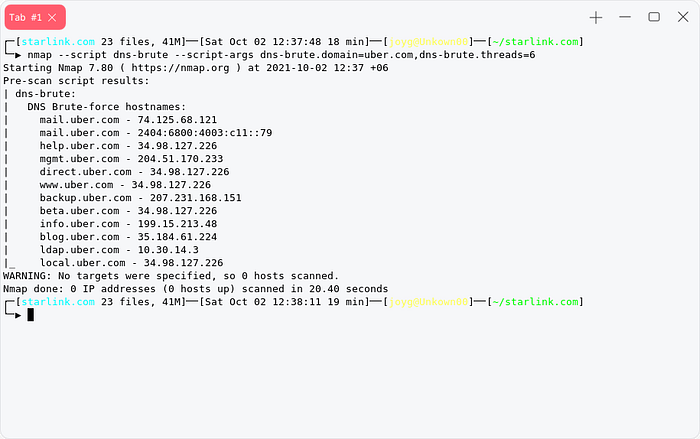
and there is chinese website which does the subdomain brutefoce for us
after collecting all the subdomains actively and passively our first task is to probe them to detect if those domain are using http or https. We can use httprobe for that.
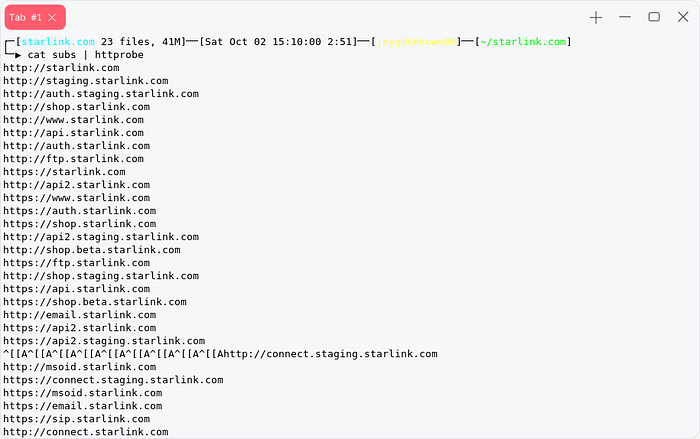
ASN Lookup
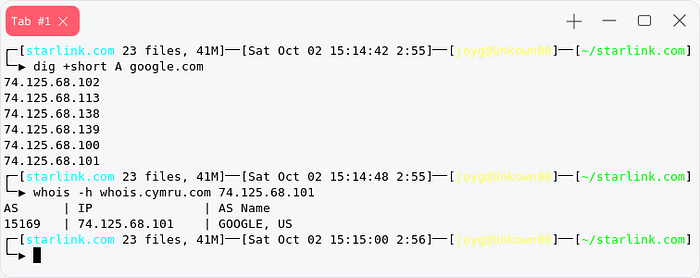
There are many ways to find asn number of a company , asn number will help us to retrieve targets internet asset . We can find asn number of a company using dig and whois , but most of the time these will give you a hosting provider asn number.

But You can find a cloud company asn with this Technic cause they host on their on server.
Example : google.com
Now lets skip those useless talk , we can extract asn ipdata of a target company using a free api called asnlookup.com.
http://asnlookup.com/api/lookup?org=starlinkafter extracting its ip range just select one ip from them without the subnet and paste it with
whois -h whois.cymru.com 1.1.1.1it will give you asn number of the target company.
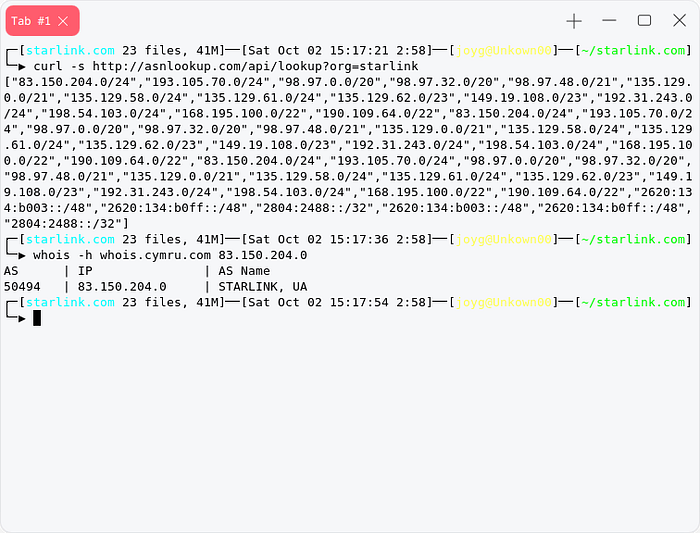
You can use the api using curl or my python3 script
so where we can use this asn number?
we can use this asn number on hackers search engine like shodan to get more extracted information about the target companies internal network.
Shodan
asn:AS50494Censys
autonomous_system.asn:394161Target Visualize/Web-Screenshot
After Enumerating subdomains/domains we need to visualize those target to see how the use interface look like , mostly is the subdomain is leaking any important information or database or not.sometime on domain/subdomain enumeration we got like 2k-10k subdomains its quite impossible to visit all of them cause it will take more than 30–40 hour , there are many tools available to screenshot those subdomains from subdomains list.
Its quite fast and doesn’t require any external dependency.

Alternatives:-
Eyewitness
[download-eyewitness] https://github.com/FortyNorthSecurity/EyeWitness ./EyeWitness -f subdomains.txt --webWebscreenshot
[download-webscreenshot] pip3 install webscreenshot webscreenshot -i subdomains.txtCrawling & Collecting Pagelinks
A url or pagelinks contains many information . Some time those pagelinks contains parameter , endpoint to some sensitive information disclosure etc etc. There are lots of tool available to crawl or collect pagelinks .
Its a golang based crawler well known for its speed. it also can collect subdomains from the page thats why i like it most.The URLs are extracted by spidering the application,parsing robots.txt files and parsing sitemap.xml files.
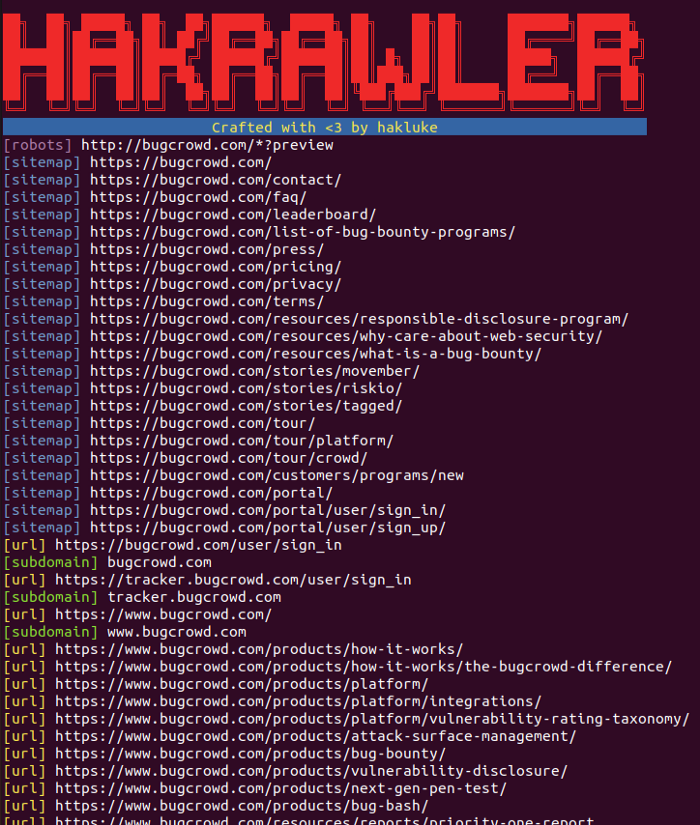

Lets now see those passive links extractor , these extractor usage alien-vault , waybackurls,etc to collect pagelinks.
This one use archive.org’s wayback engine to collect pagelinks.
Javascript Files Crawling/Sensitive data extracting from js
Its not a different part from website crawling we can gather javascript file from those crawling tools.
We can use previously discussed gospider to crawl javascript file from webpage
gospider -s https://target.com --js --quiet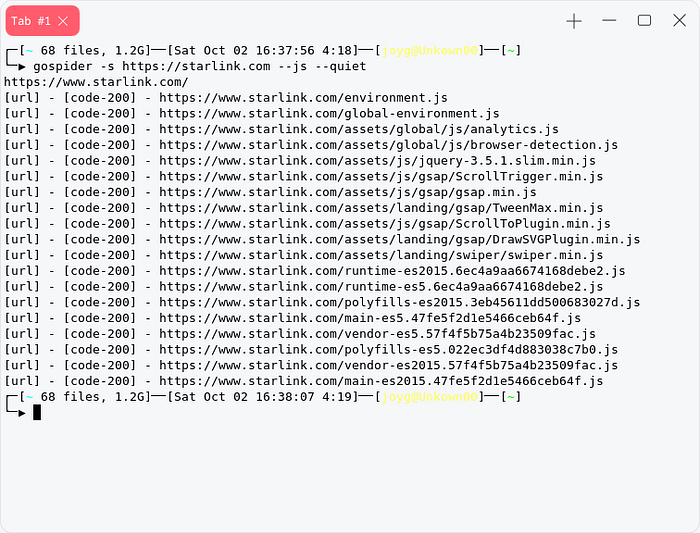
or We can use Waybackurls/gau to collect javascript file.
echo starlink.com | gau | grep '\.js$' | httpx -status-code -mc 200 -content-type | grep 'application/javascript'
or
gau target.tld | grep "\\.js" | uniq | sort -u waybackurls targets.tld | grep "\\.js" | uniq | sort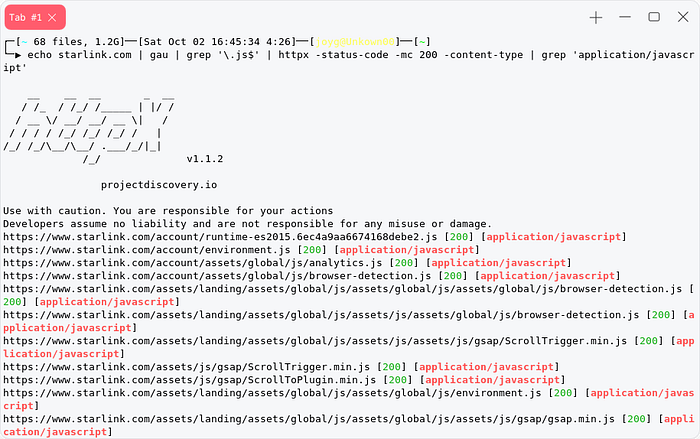
or We can use well known and popular tools for collecting js files
cat subdomains | getJS --complete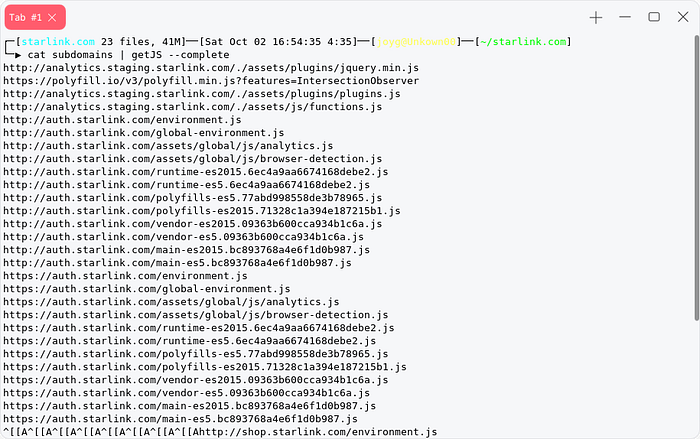
or My Python3 script to filter js from a webpage
After collecting javascrip files our first task is to find sensitive infomation from the javascript file , sensitive information can be related to api key , auth token, active cookie , etc.
You can grub api key using this method
[see-the-list] https://github.com/System00-Security/API-Key-regex cat file.js | grep API_REGEXor using Secretfinder
Sometime those javascript files also contains endpoints we can extract those endpoints using bash.
cat file.js | grep -aoP "(?<=(\"|\'|\`))\/[a-zA-Z0-9_?&=\/\-\#\.]*(?=(\"|\'|\`))" | sort -uor We could use Relative-url-extractor
cat file.js | ./extract.rbParameter discovery
Web applications use parameters (or queries) to accept user input. We can test for some vulnerability on params like xss,sql,lfi,rce,etc.
[download-arjun] pip3 install arjun arjun -i subdomains.txt -m GET -oT param.txt #for multiple targetarjun -u target.com -m GET -oT param.txt #for single target [-m ] parameter method
[-oT] text format output # you can see more options on arjun -h
or or or we can use the bruteforce method for param discovery using Parameth.
Subdomain Cname extraction
extracting cname of subdomain is usefull for us to see if any of these subdomain is pointing to other hosting/cloud services. So that later we can test for takeover.
We can do that by using dig
dig CNAME 1.github.com +shortso we have multiple subdomain , we can use xargs to make this automate with multitask
cat subdomains.txt | xargs -P10 -n1 dig CNAME +shorton these cname file we are gonna filter these cname like
“\.cloudfront.net” “\.s3-website” “\.s3.amazonaws.com” “w.amazonaws.com” “1.amazonaws.com” “2.amazonaws.com” “s3-external” “s3-accelerate.amazonaws.com” “\.herokuapp.com” “\.herokudns.com” “\.wordpress.com” “\.pantheonsite.io” “domains.tumblr.com” “\.zendesk.com” “\.github.io” “\.global.fastly.net” “\.helpjuice.com” “\.helpscoutdocs.com” “\.ghost.io” “cargocollective.com” “redirect.feedpress.me” “\.myshopify.com” “\.statuspage.io” “\.uservoice.com” “\.surge.sh” “\.bitbucket.io” “custom.intercom.help” “proxy.webflow.com” “landing.subscribepage.com” “endpoint.mykajabi.com” “\.teamwork.com” “\.thinkific.com” “clientaccess.tave.com” “wishpond.com” “\.aftership.com” “ideas.aha.io” “domains.tictail.com” “cname.mendix.net” “\.bcvp0rtal.com” “\.brightcovegallery.com” “\.gallery.video” “\.bigcartel.com” “\.activehosted.com” “\.createsend.com” “\.acquia-test.co” “\.proposify.biz” “simplebooklet.com” “\.gr8.com” “\.vendecommerce.com” “\.azurewebsites.net” “\.cloudapp.net” “\.trafficmanager.net” “\.blob.core.windows.net”
Domain/Subdomain Version and technology detection
Its important to scan for domain/subdomain version and technology so that we can create a model for vulnerability detection , how we are gonna approach our target site.
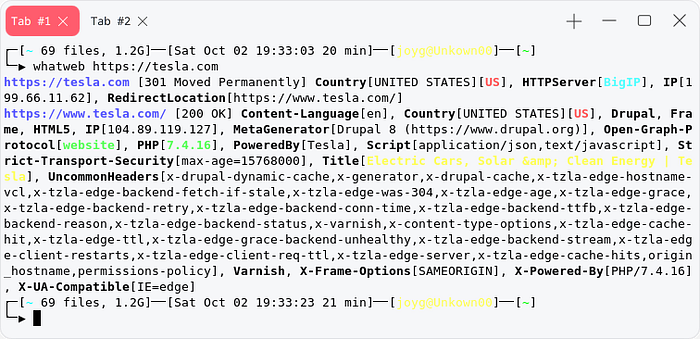
Wappalyzer
Its a popular technology and version detection tool , there is chrome extension so that we can see the website we are visiting its technology.
[install-wappalyzer] npm i -g wappalyzer
wappalyzer https://uber.com #single domain
cat subdomain.txt | xargs -P1 -n1 wappalyzer | tee -a result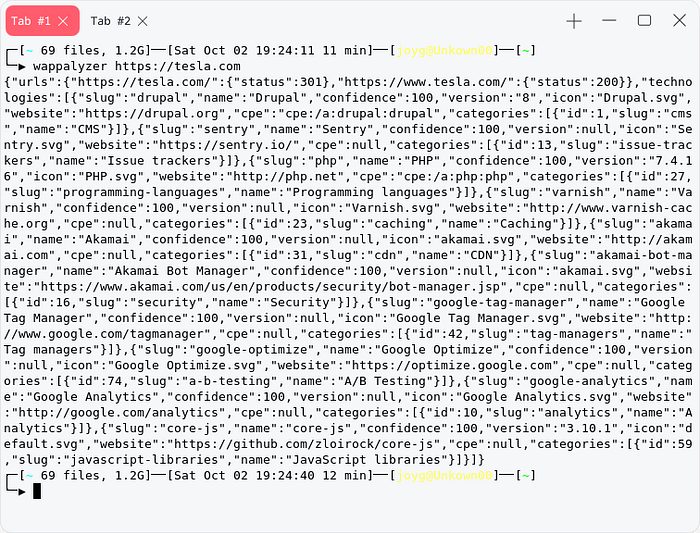
WAD [Web application detector]
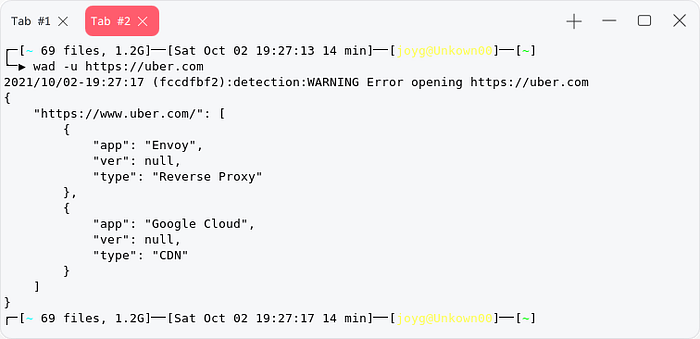
Sensitive information discovery
Some target unintentionally contains sensitive information like database dump, site backup,database backup , debug mode leak , etc. sometime searchengine like google,shodan,zoomeye,leakix contains some sensitive information of the site or leak something .
Scanning for Web-app backup
We can use ffuf to fuzz for database dump , common wordlist to scan for database dump. We will use this wordlist for fuzzing.
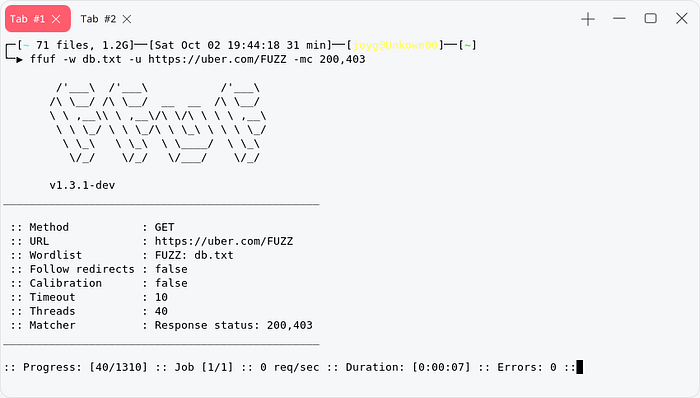
for multiple url with ffuf , we can use xargs to do that, but the subdomains should contains /FUZZ at the end of the domain.
cat subdomains | xargs -P1 -n1 ffuf -w backup.txt -mc 200,403 -u We are filtering 200,403 response cause there is some way to bypass 403 unauthorized , you cant try the bypass method with this tool.
We all know the well known fast and popular search engine is google.com, this search engine collects and index mostly every website available on surface web , so we can use it to find sensitive information about a domain. we will use google advance search also known as dorking.
Publicly Exposed Documents
site:target.tld ext:doc | ext:docx | ext:odt | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csvDirectory listing
site:target.tld intitle:index.ofExposed Configuration file
site:target.tld ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini | ext:envFor Automated Process We can use
Github Recon
many of the target has github repo some of them are opensource project , sometime those github code project leaks their private api key for many services or sometime the source code disclose something sensitive thats why github is not only code vault it’s also pii vault for hackers.You can do the recon 2 way on github one is manually one is automatically ,using github dorking tools.
Github Recon helps you to find PII more easily.
Shodan Recon
shodan is most usefull search engine for hacker, you can find many sensitive and important information about the target from shodan , like google and github shodan also has advance search filter which will help us to find exact information about exact target.
Shodan dorks
we can use these filter to create a perfect query to search vulnerability or sensitive information on shodan.
hostname:uber.com html:"db_uname:" port:"80" http.status:200 # this will find us a asset of uber.com with db_uname: with it with staus response code 200http.html:/dana-na/ ssl.cert.subject.cn:"uber.com" # this will find us Pulse VPN with possible CVE-2019-11510html:"horde_login" ssl.cert.subject.cn:"uber.com" # this will find us Horde Webamil with possible CVE 2018-19518We can Repet the second 2 process also with product filter Ex:product:"Pulse Secure" ssl.cert.subject.cn:"uber.com"http.html:"* The wp-config.php creation script uses this file" hostname:uber.com # this will find us open wp-config.php file with possible sensitive credential
Suppose we know a active exploit for apache 2.1 , to check manually to see which of our target subdomain is using apache 2.1 will cost us time and brain , for that we can create a dork on shodan to help us in this subject , Example : server: “apache 2.1” hostname:”target.com” we can replace the hostname to get more accurate result for target.com using ssl.cert.subject.cn:”target.com” , this will check if the target host/server contains target.com on their ssl or not.
leakix is most underrated search engine for leaks and misconfiguration , it can find the leak for .git .env phpinfo() and many others. you can use it directly from the browser or use its client.
You can use my python3 based client which grubs the result directly from web
You can convert all the subdomain hostname to ip then start a bulkscan with them , or collect CIDR/Ip range from asn and start scanning to find leak.
[Simple Way To do recon like a pro ]
